Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference.
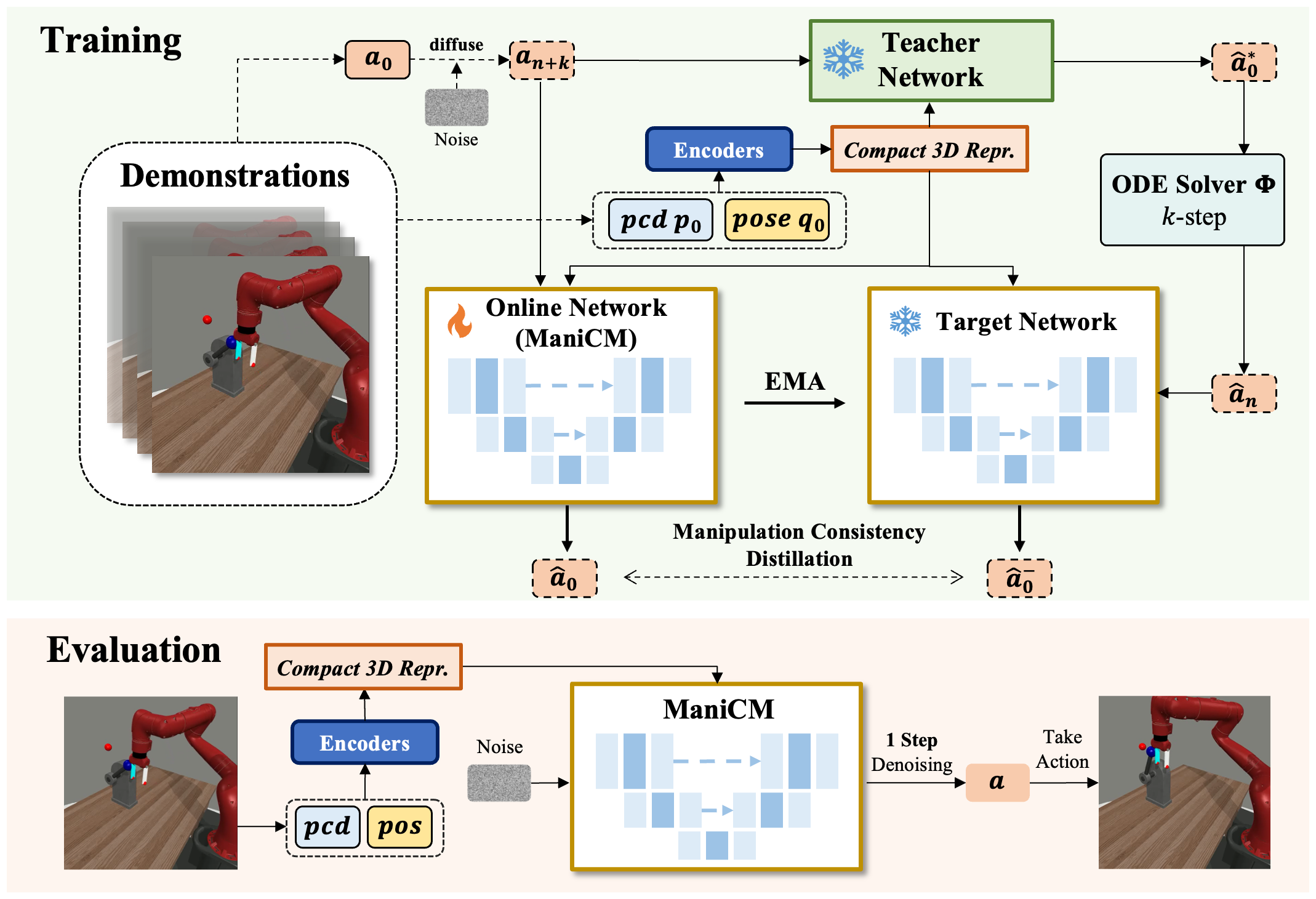
Given a raw action sequence a0, we first perform a forward diffusion to introduce noise over n + k steps. The resulting noisy sequence an+k is then fed into both the online network and the teacher network to predict the clean action sequence. The target network uses the teacher network’s k-step estimation results to predict the action sequence. To enforce self-consistency, a loss function is applied to ensure that the outputs of the online network and the target network are consistent.
The author team would like to acknowledge Zhixuan Liang and Yao Mu from the University of Hong Kong for their helpful technical discussion and suggestions.
Our code is built upon
3D Diffusion Policy,
MotionLCM,
Latent Consistency Model,
Diffusion Policy,
VRL3,
Metaworld,
and
ManiGaussian.
We would like to thank the authors for their excellent works.
@article{lu2024manicm,
title={ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation},
author={Guanxing Lu and Zifeng Gao and Tianxing Chen and Wenxun Dai and Ziwei Wang and Yansong Tang},
journal={arXiv preprint arXiv:2406.01586},
year={2024}
}